AUTOGRAMM PARSING PROJECT CONTRIBUTION
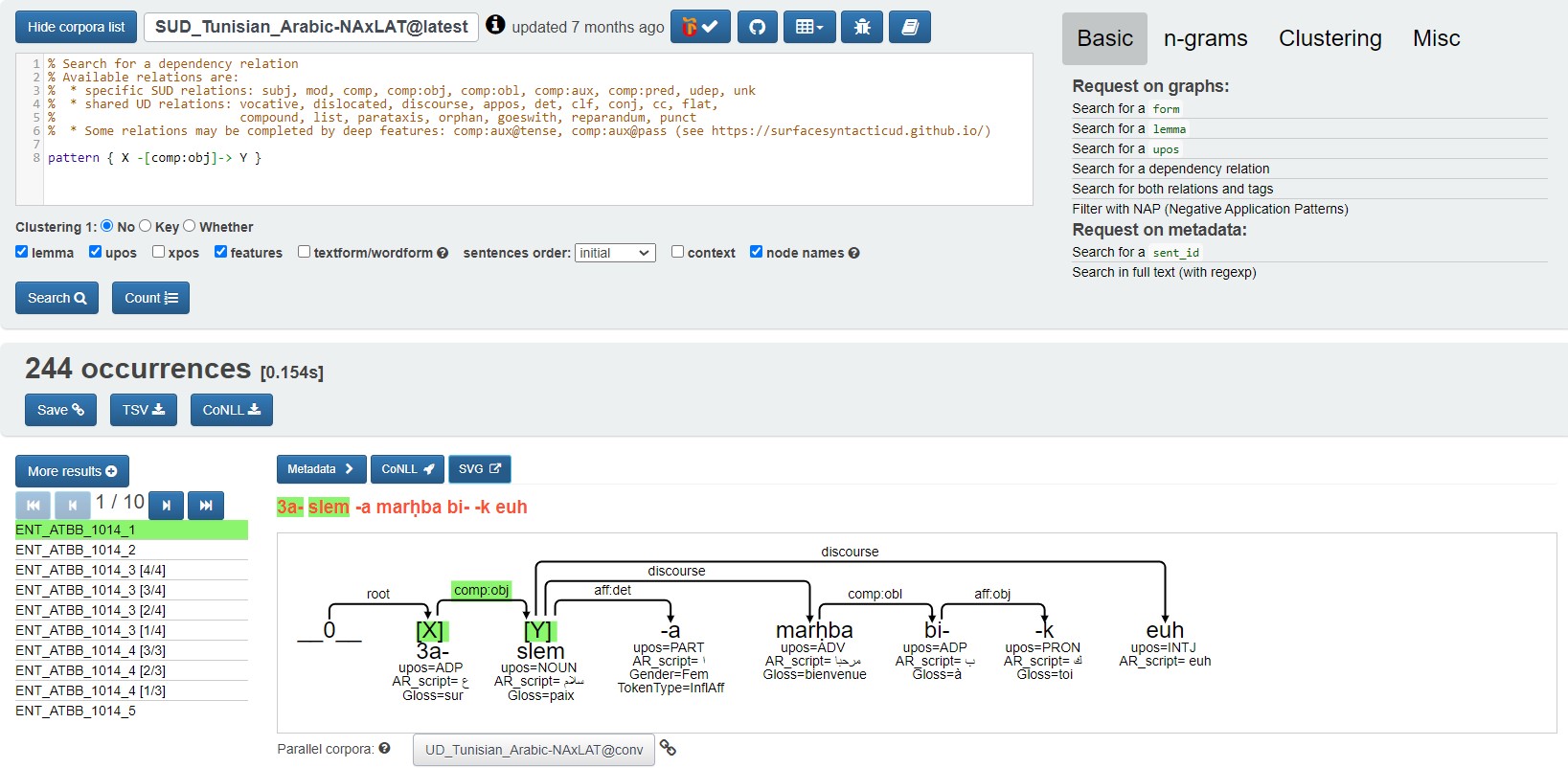
Key tool of the Autogramm project: Grewmatch. Example of research on syntactic patterns in a Tunisian treebank
Project description
In the Autogramm project, my contributions were pivotal in advancing the automated extraction of descriptive grammars and grammatical descriptions from annotated corpora. My work focused on several key areas, notably the training of machine learning models, processing of linguistic data, and developing annotation schemes.
I designed scripts for the conversion and processing of Elan files, which are derived from voice recordings. This task was crucial for transforming raw linguistic data into a structured format suitable for further analysis. My work ensured that the voice recordings were accurately processed, facilitating the creation of a reliable and usable treebank.
I also conceived an annotation schema that bridged the gap between linguist labels and machine learning algorithms. This schema was designed to translate the nuanced labels provided by linguists into formats that could be readily utilized by ML algorithms, enhancing the integration of linguistic expertise with computational methods.
Throughout the project, I worked on languages Gbaya and Beja, contributing to the development of treebanks and grammatical descriptions for these languages. My efforts supported the project's goal of extracting and analyzing grammatical patterns from under-resourced languages, thereby enriching the typological and comparative studies conducted within the project.
Discover more about this project and click on the button below to access the GitHub Repository.
Explore More Projects
If you're interested in exploring more projects, please select another project from the dropdown menu.