LLM INFERENCE ACCELERATION
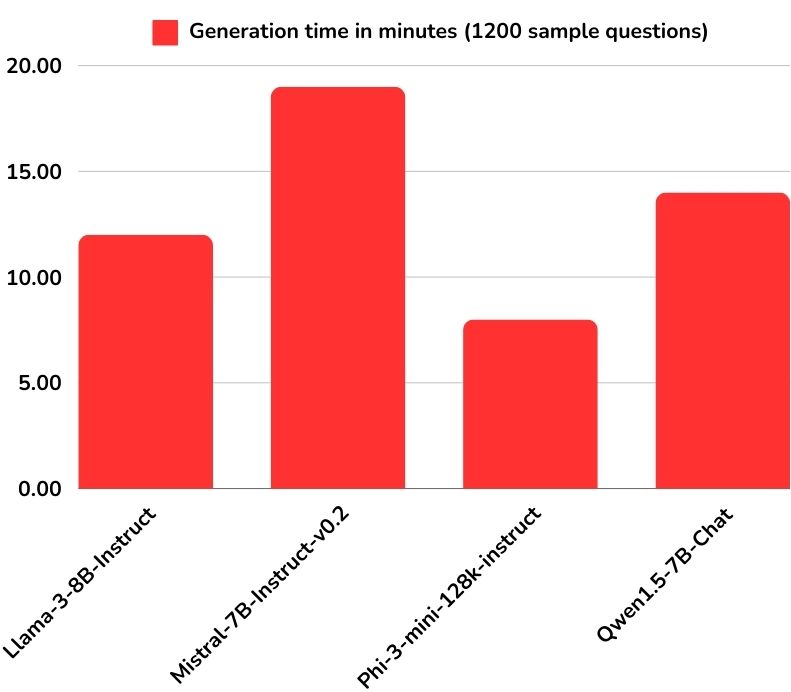
Generation time in minutes (1200 sample questions)
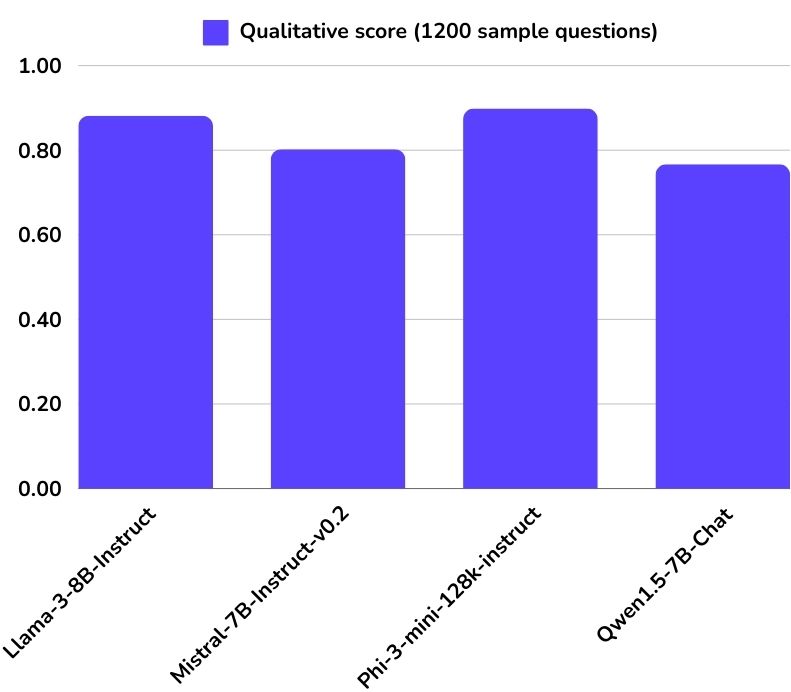
Qualitative score (1200 sample questions)
Project description
This project aims to significantly boost the inference speed of open-source LLMs. We achieve this by transitioning from the traditional Multi-head Attention mechanism to the Grouped Query Attention mechanism, following insights from the paper GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.
The process begins with evaluating the LLM's performance using responses to the SQuAD v2 dataset. Responses are compared with expected answers using cosine similarity, with preliminary checks performed using OpenAI's ADA model. For scores within the range of 0.70 to 0.85, additional verification is done using GPT-3.5 to confirm accuracy, ensuring both model evaluation speed and accuracy.
We then refine the model by mean pooling the weights of the key and value components within the Multi-head Attention mechanism, using a custom script. Due to resource limitations, we utilize Low-Rank Adaptation for fine-tuning. This involves two stages: unsupervised fine-tuning on the Slim Pajama dataset, followed by instruction-based fine-tuning on the Awesome dataset.*
Finally, we measure the model's performance, focusing on both the quality of generated responses and the speed of inference.
Discover more about this project and click on the button below to access the GitHub Repository.
*This project is ongoing and is being developed as part of an internship at an R&D company based in Lyon.
Explore More Projects
If you're interested in exploring more projects, please select another project from the dropdown menu.